利用イメージ
補足資料
ウェブカタログ

2007年6月28日
パーソナルメディア株式会社
〒141-0022 東京都品川区東五反田1-2-33 白雉子ビル
TEL.03-5475-2185 FAX.03-5475-2186
E-mail:[email protected]
http://www.chokanji.com/
〒141-0022 東京都品川区東五反田1-2-33 白雉子ビル
TEL.03-5475-2185 FAX.03-5475-2186
E-mail:[email protected]
http://www.chokanji.com/
パソコン用の総合文字検索ツール「超漢字検索」を新発売
~中国、韓国、欧州などの文字や発音記号も簡単入力~
|
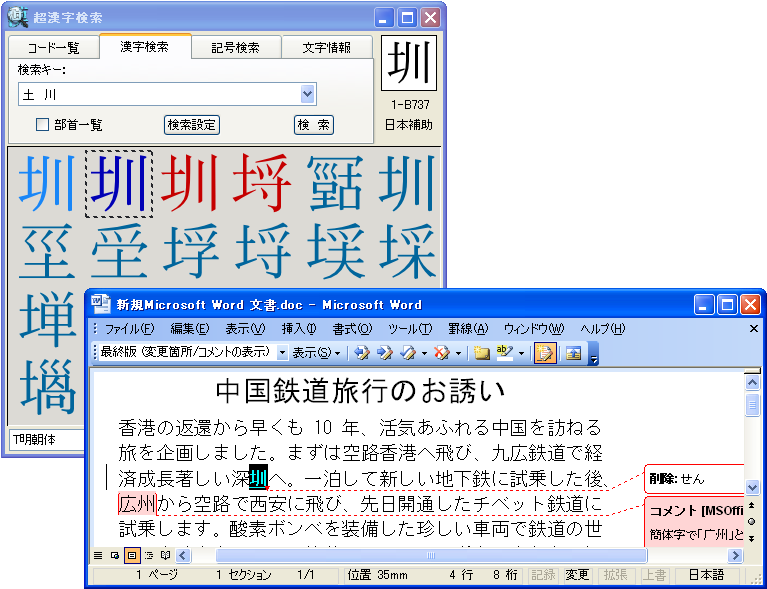
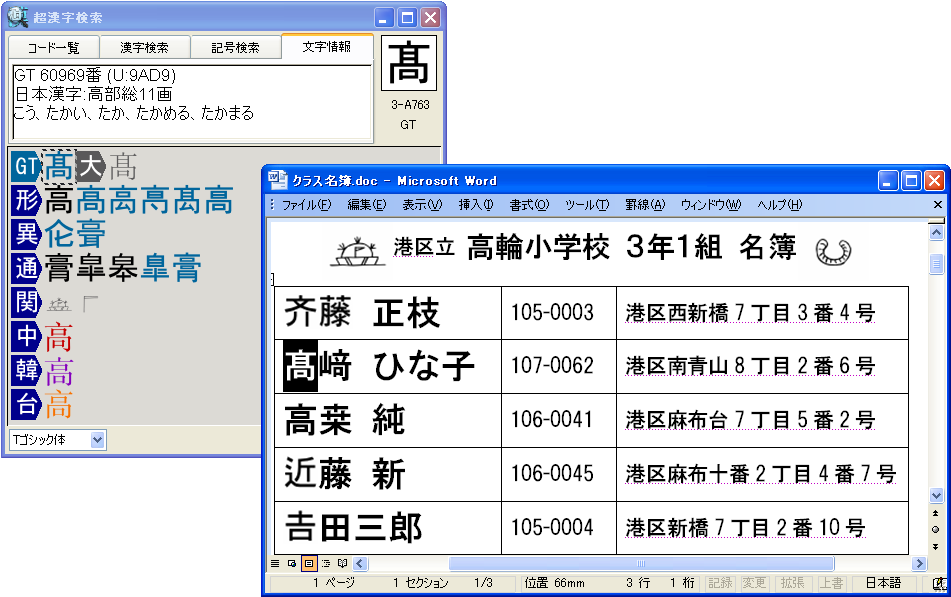
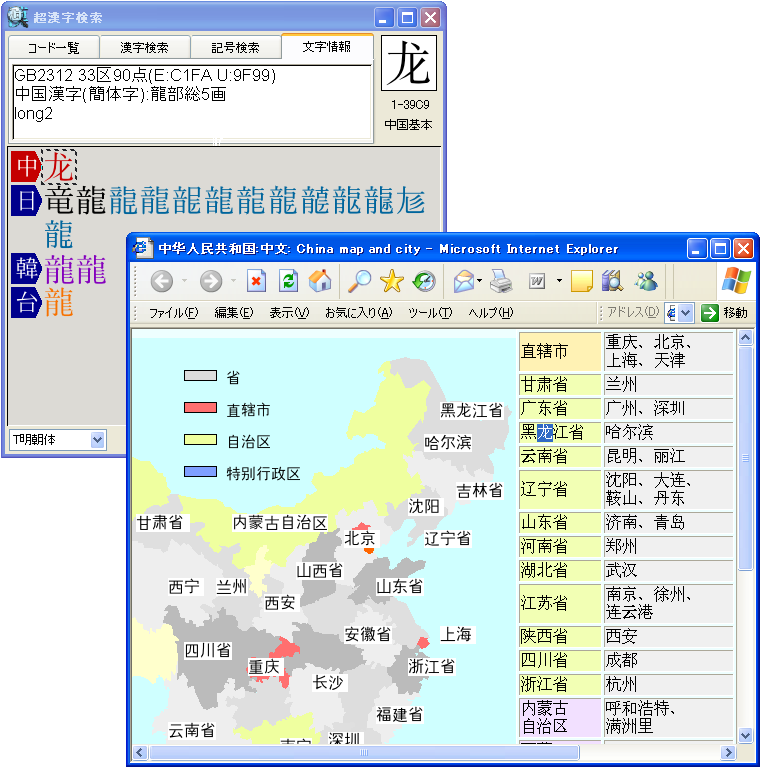
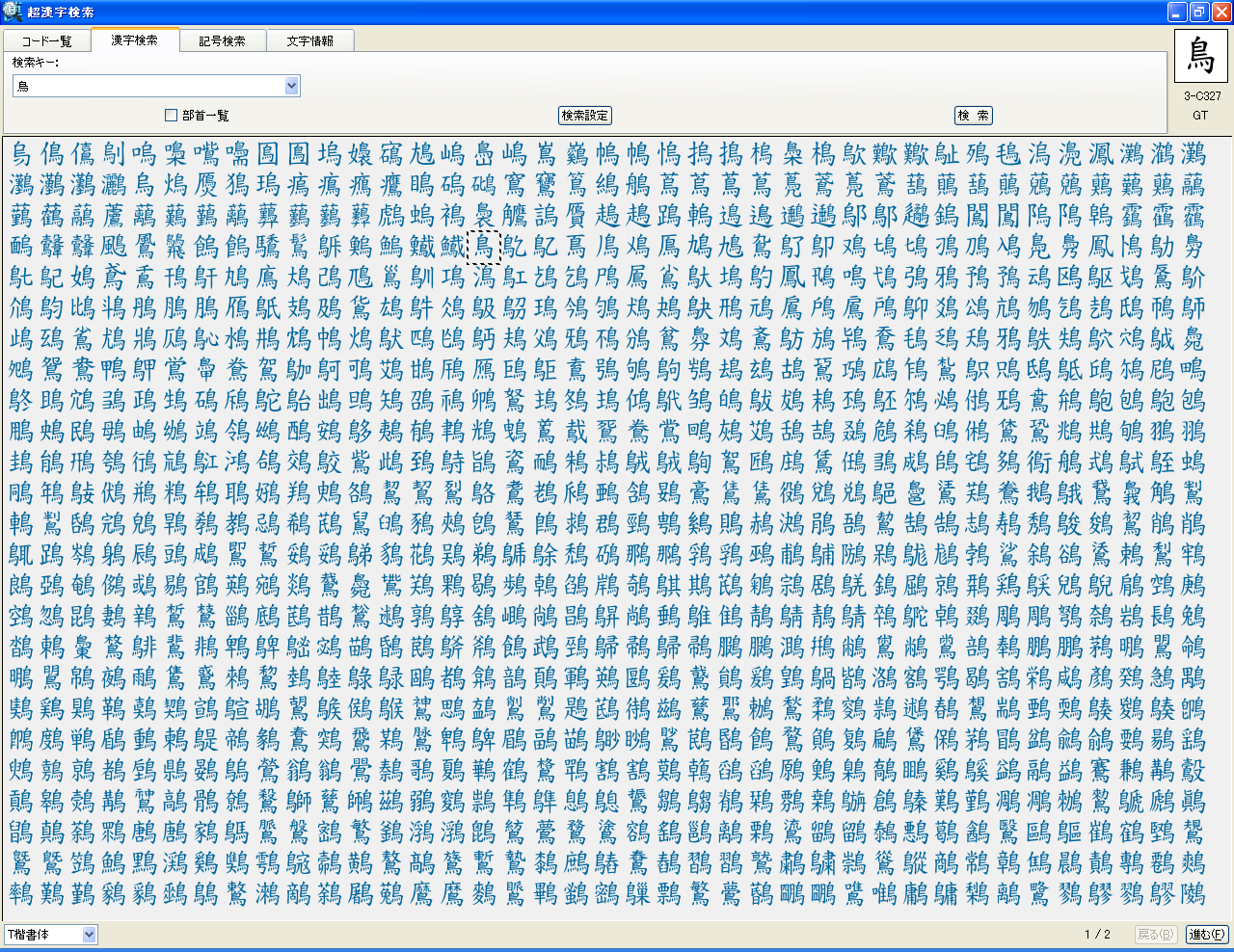
ソフトウェアメーカーのパーソナルメディア株式会社(代表取締役:泉名達也、本社:東京、電話:03-5475-2185、資本金 1,000万円)は、読めない漢字や異体字、世界各国の文字や記号などを、読みや部首はもちろん、漢字の一部や関連字情報からすばやく検索してワープロソフトなどに入力できるWindows用の総合文字検索ツール「超漢字検索」(http://www.chokanji.com/ckk/)の開発に成功し、明日6月29日(金)よりダウンロード販売を開始いたします。
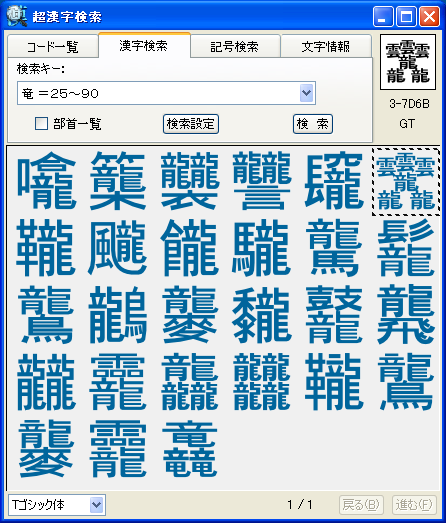
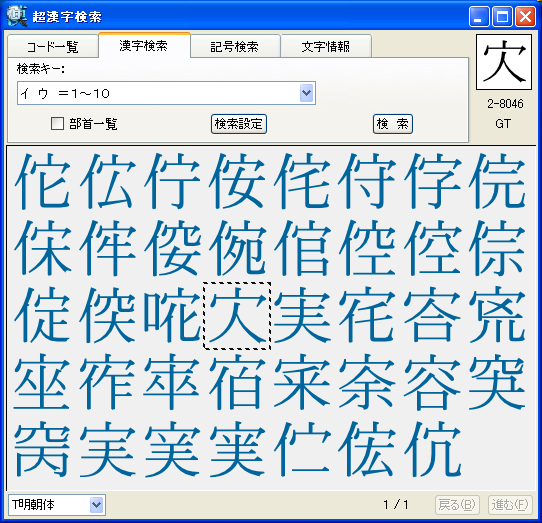
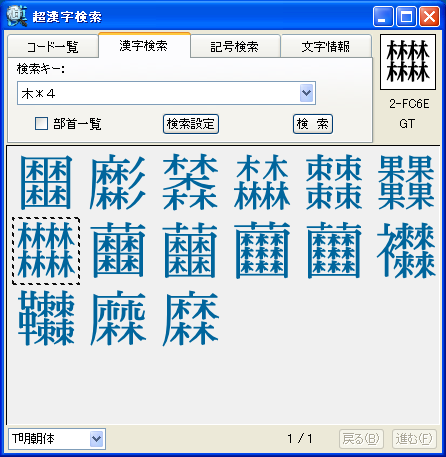
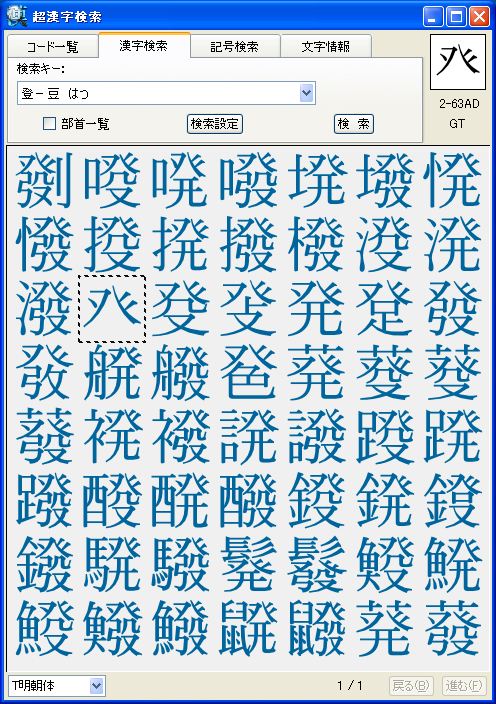
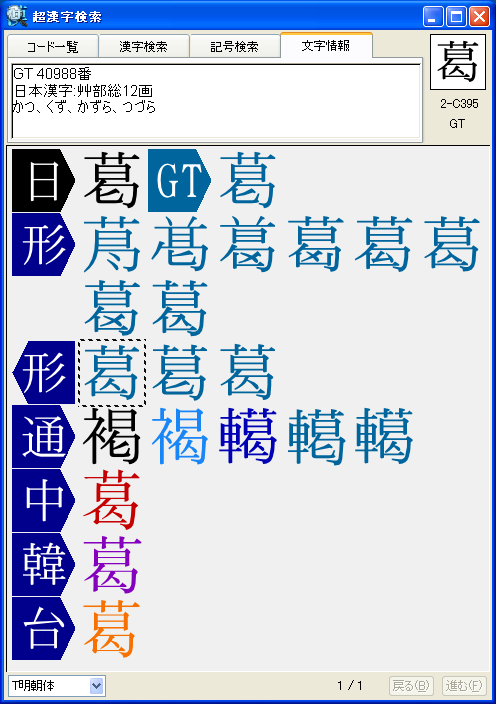
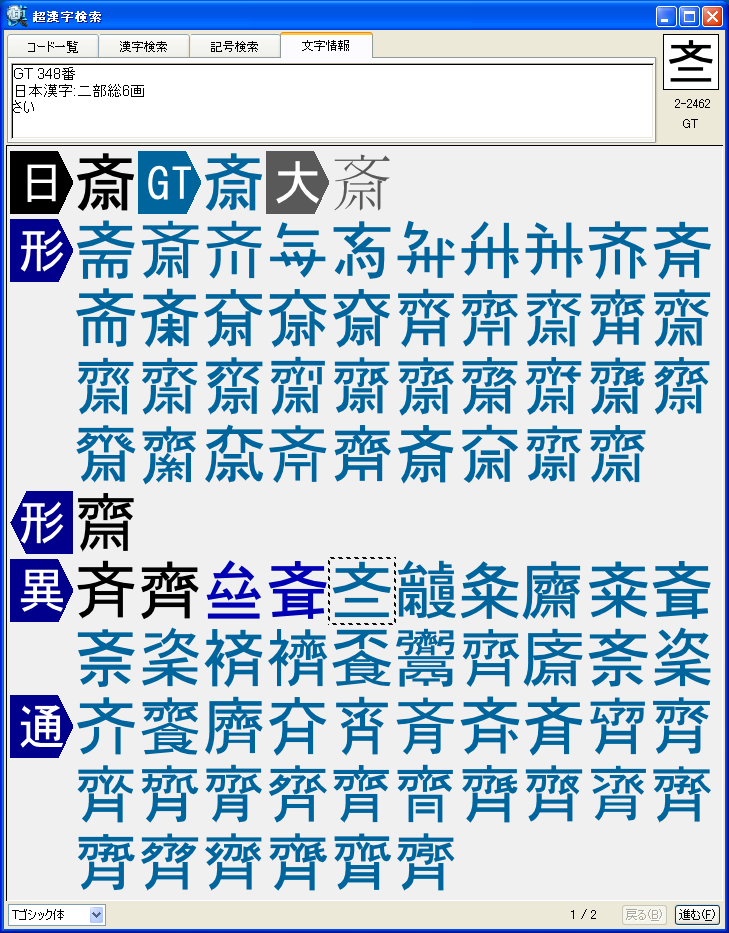
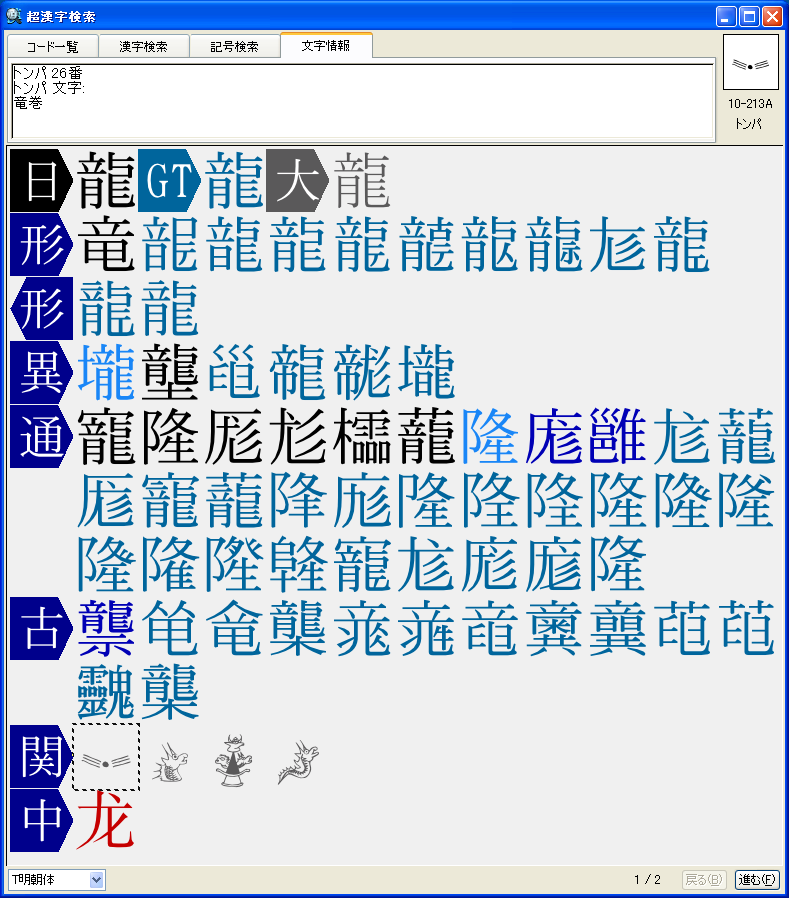
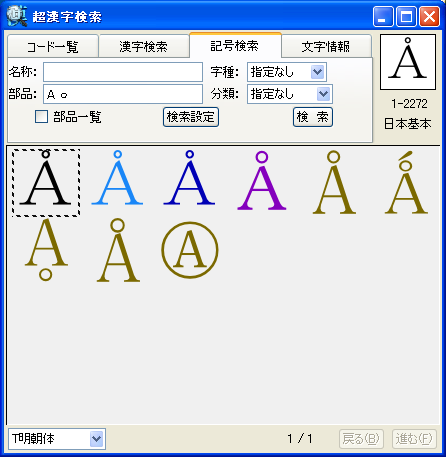
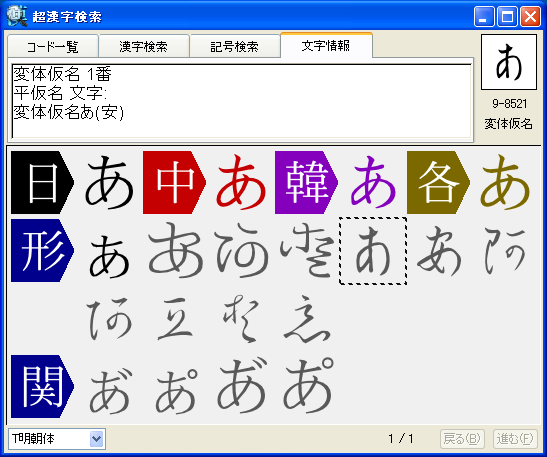
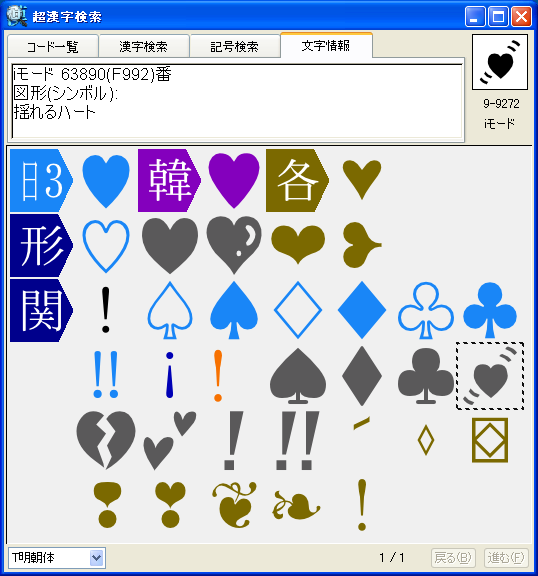
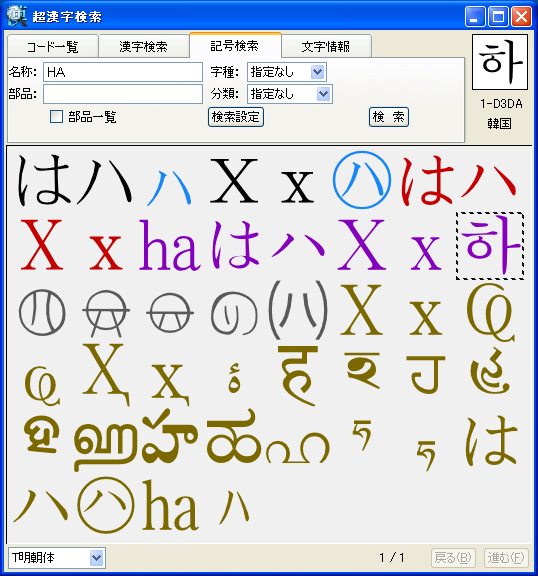
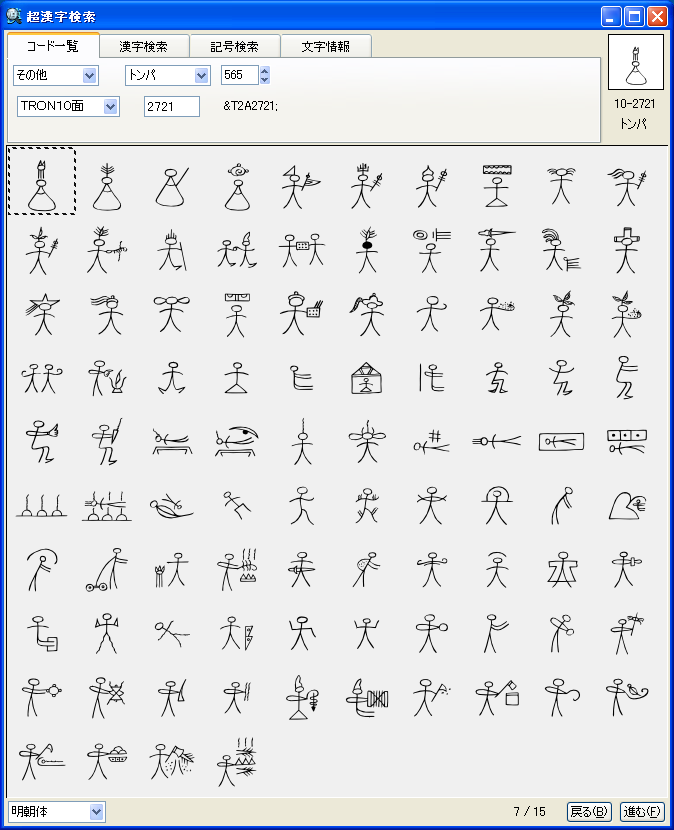
パソコンで漢字を入力する際、通常はかな漢字変換を使いますが、読み方がわからない文字や特殊な読み方をする人名用漢字や固有名詞では、かな漢字変換を使っても目的の漢字をなかなか見つけ出せないケースが多々あります。この点を補うため、WindowsのIME(かな漢字変換を含む文字入力システム)には、画数や部首による漢字の検索や、手書き文字認識による漢字入力機能も用意されていますが、目的の文字を見つけるのに時間がかかるなど、なかなか思うように入力できないのが実情です。 新発売の「超漢字検索」は、多文字を扱えるトロンOS「超漢字」上で永年蓄積したノウハウを活かした、Windows用の強力な文字検索ソフトウェアです。漢字の読みや画数はもちろん、漢字の一部(*1)や異体字、それらの組み合わせなど、漢字を見て直感的に得られる情報を検索キーとして、18万(*2)の漢字や文字から目的の文字を素早く見つけ出すことができます(*3)。たとえば「矩」(*4)という文字を入力する際、読みがわからなくても、「矢」「巨」から検索することにより容易にこの文字を入力できます。また、強力な文字情報機能により、漢字の読みや部首、画数、文字コードなどが分かるほか、異体字や対応する中国、韓国の漢字なども一覧できます。この機能は、たとえば「穂」の異体字である「穗」を入力する場合や、「電」の中国簡体字を入力する場合に役立ちます。さらに、「超漢字検索」には3000字以上に達する豊富な記号(*5)や漢字以外の文字を対象とした専用の検索機能が備わっており、欧州各国で使われる文字や発音記号の入力も容易に行うことができます。 このようにして「超漢字検索」で見つけた文字は、コピー&ペーストの操作によりWordなどのWindows用アプリケーションに貼り込んで利用できます。この時、Unicode2.0範囲内(*6)の文字は文字コードにより表現される通常の文字として貼り込めますが、それ以外の文字、たとえば大漢和辞典(*7)収録文字(約5万字)やGT文字セット(*8)の漢字(約78,000字)、変体仮名、携帯電話のiモード絵文字、トンパ文字(*9)等については、文字を画像イメージに変換して貼り込むか、TRONコードと呼ばれる文字番号(&Txxxxxx;と表現)に変換して貼り込みます(*10)。また、「T書体フォント」(*11)により、約78,000字の明朝体、ゴシック体、楷書体を図形イメージで利用することができます。 「超漢字検索」の発売日は6月29日(金)で、Vector(*12)およびパーソナルメディアのウェブサイトにてダウンロード販売を行います。「超漢字検索」の標準価格は税込6,300円(本体価格6,000円)ですが、2007年8月31日正午までにパーソナルメディアから直接ご購入された場合に限り、税込5,250円(本体価格5,000円)にてお求めいただける発売記念キャンペーンを実施いたします。また、ご購入前に10日間の試用期間が設けられており、本ソフトウェアの機能と使いやすさを無償でお試しいただけます。このほか、自治体様や法人のお客様による業務目的での利用を想定した「超漢字検索カスタム版」の受注も承ります。「超漢字検索カスタム版」では、お客様が既にお持ちの外字などを検索対象文字として追加することにより、お客様の文字環境に最適な多漢字の入力ツールをご提供いたします。Linuxなど他のOSへの移植も可能です。
| ||||||||||||||||||||||||||||
|
■「超漢字検索」の利用イメージ
| ||||||||||||||||||||||||||||
|
■補足資料
| ||||||||||||||||||||||||||||
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ■ | TRON は "The Real-time Operating system Nucleus" の略称です。 |
| ■ | 超漢字はパーソナルメディア株式会社の商標です。 |
| ■ | Windows, Word は米国 Microsoft Corporation の米国およびその他の国における登録商標または商標です。 |
| ■ | 本資料に記載された製品の仕様、画面イメージ、価格などは、発表日現在のものです。最終的に販売される製品では、変更されることがありますので、あらかじめご了承ください。ご購入の際は、最新情報をご確認ください。 |
以上
| は、トロン仕様製品の統一マークです。(http://www.tron.org/) |